|
|
This notebook was created by Jean de Dieu Nyandwi for the love of machine learning community. For any feedback, errors or suggestion, he can be reached on email (johnjw7084 at gmail dot com), Twitter, or LinkedIn.
Intro to Artificial Neural Networks and Deep Learning¶
Deep Learning is the study of Artificial Neural Networks(ANNs). It is a subset of Machine Learning (ML), ML being a subset of Artificial Intelligence.
Inspired by the human brain's biological neuron, ANNs has become the building block of modern intelligent systems, from our smartphones that can accurately identify our faces and voices, streaming services (like YouTube and Netflix) that know exactly what we want to watch, cars that can see the visual world and drive themselves, and not to mention AlphaGo that won world chess competition.
This notebook will introduce a high level overview of Deep Learning.
1. Why Deep Learning¶
Deep Learning is used to extract the patterns in (a huge amount of) data. Its potential has been seen in complex problems such as vision oriented and natural language.
Let's take an example to develop more intuitive understanding of why deep learning has became so popular. Let's say that as an Engineer, you are asked by your city state to build a program that can recognize car and truck moving in a given road. The program can later be deployed in a less loads-road to warn trucks that pass there that the road was not designed for these types of vehicles.
With normal programming, you would have to provide and to write all instructions (codes) of that particular program. The chance (close to reality) is that it would be hard, mostly because there are different types of cars and trucks and each can be unique in its ways, which can make it hard to write the rules forming such program.
How can deep learning solve that? Well, by feeding the images of cars and trucks to a deep learning model, say a convolutional neural network (more on this latter), it can learn the underlying features of cars and trucks, and thus will be able to recognize each and each. We will see this in practice in later notebooks.
With the advent of the computation power, both paid and free (Google Colab & Kaggle), open source datasets, and intelligent frameworks such as TensorFlow and PyTorch, it has become very much possible to do deep learning, even at personal level. This was not possible a decade ago.
2. A Single Hidden Layer Neural Network¶

Image: A Single hidden layer neural network, Wikimedia
The image above represent a single hidden layer neural network. Usually, any typical neural network has 3 main layers:
Input layer that takes the input data. The input data can be image, text, or numbers but ofcourse whatever the data type is, the input to a neural network will always have to be in a numeric format.
Hidden layer that is between the input and the output layers. There is a alot of computations that takes place in this layer but that is not in the scope of this notebook.
- Output layer that give the output of the network. Output can be a numerical number (mostly in regression problem) or a probability (mostly in classification problem).
A neural network having more than one layer is commonly referred to Deep Neural Network(DNN). Also, it is important to note that a neural network can have multiple input layers, multiple hidden layers, and multiple output layers. The structure of how a neural network has to be or its size will mostly depend on the type of a problem being solved.
With the exception of the input layer, you will find something called activation function being applied to hidden and output layers. What is an activation function?
3. Common Activation Functions¶
Activation functions are used to introduce nonlinearities in the network. I like to say that they dictate the output format of a given layer.
Or simply put, these type of mathematical functions are used to make a decision of the layer's output. In later notebooks, this will certainly make sense.
Here are the 3 most used activation functions:
- ReLU(Rectified Linear Unit): This is mostly used in hidden layers and it is a default activation function in most problems that will work well in most cases. ReLU always give the positive outputs, if the input number is greater than 0, the output will be that number. If it's less than 0, the output will be 0. The whole purpose of this type of activation function is to penalize the negative numbers. ReLu has different versions such as SeLU and LeakyReLU. In most cases, ReLU can only be used in output layer when the problem is a regression type, but this is not a necessity too.
- Sigmoid: A sigmoid function gives the probabilistic output (a number between 0 and 1). It can be used in output layers of a classification problem.
- Softmax: This type of function is also used in output classification layers, but instead of giving probalistic output, its output is an actual classes. This will make sense in later notebooks.
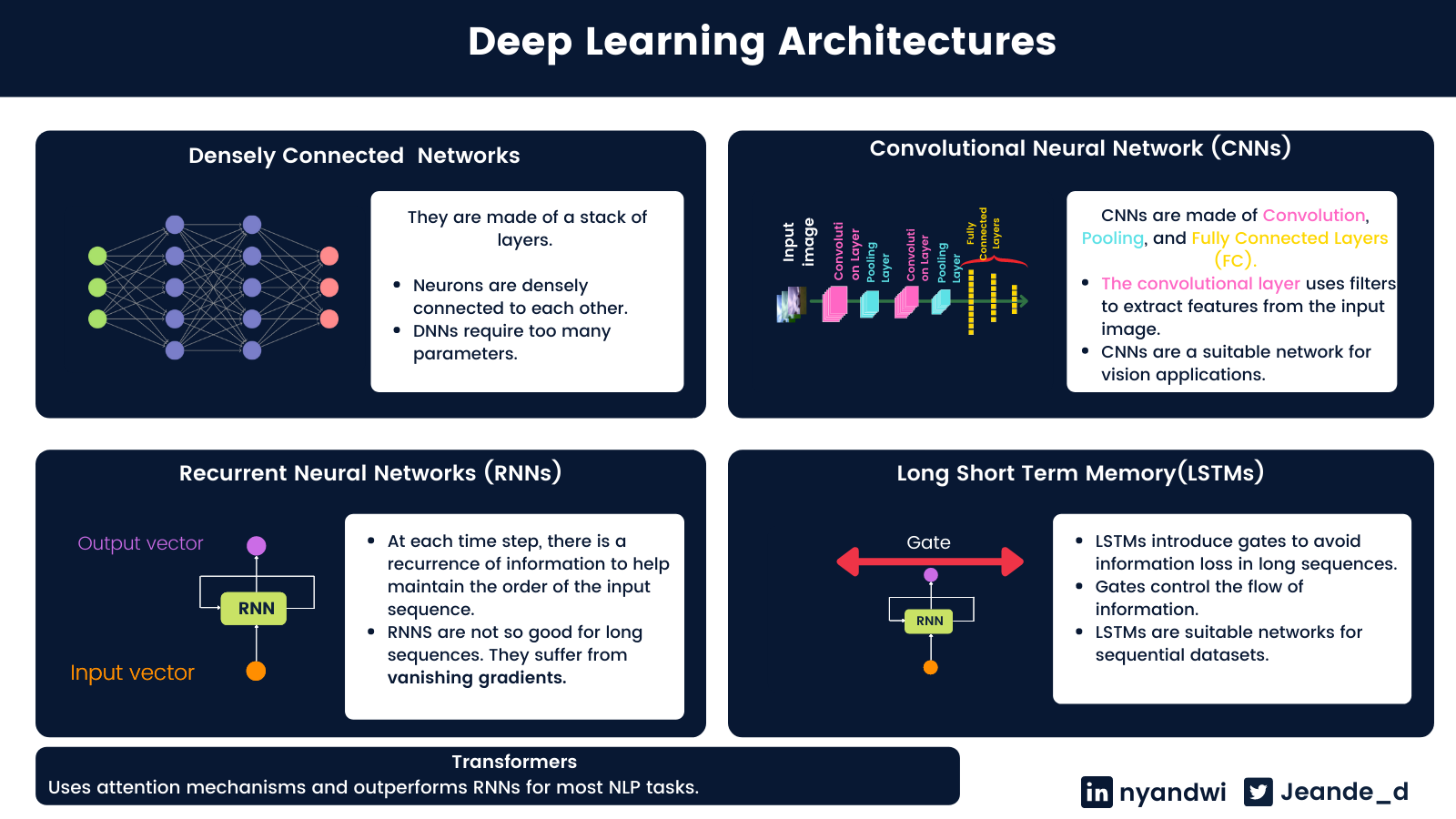
4. Types of Deep Learning Architectures¶
There are 4 main types of deep learning architectures. This is going to be a high level since they will be covered in the next notebooks.
4.1 Densely Connected Networks¶
Densely connected networks are made of stacks of layers from the input to the output.
The units (or neurons) of any layer in that type of network are connected to all other units of the next layer. This is why they are also called fully connected layers.
Densely connected layers are generally used for tabular data. Tabular data are these kinds of data that are in a tabular fashion. An example of tabular data is customer records: you have a column of names, roles, data joined, etc...
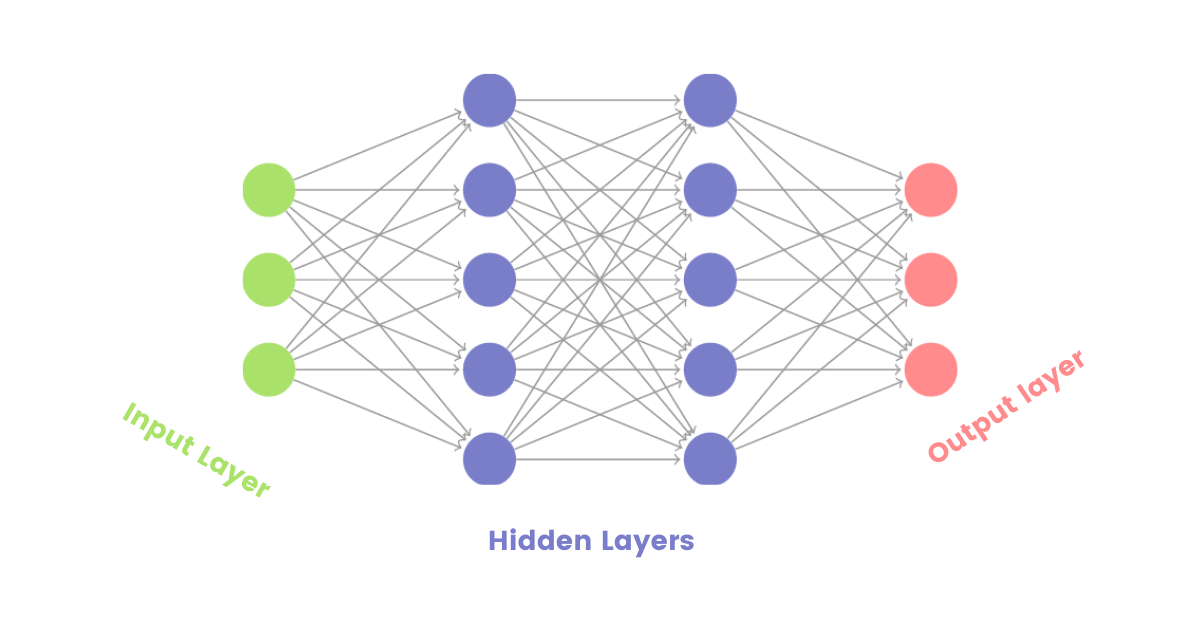 Image: Densely connected networks
Image: Densely connected networks
Dense layers are also used (in the combination of other architectures) as the last layer in either classification or regression problems. The right number of units in the last layer depends on the problem. Take an example: if you are classifying the news into 4 categories, then the last layer will have 4 units. If you are predicting the price of a house given its features, the last layer will have 1 unit.
Dense networks are mostly used in simple tasks. When it comes to complex things like image recognition or text processing, they fail because they can't hold spatial features (in image) or can't learn a sequence in text for instance. But above all, the more deep they become, they tend to have many parameters which can results in having a big network/complex computations.
4.2 Convolutional Neural Networks¶
CNN's, a.k.a Convnets are widely known as the go-to neural network architectures for computer vision tasks like image recognition and object detection, but they can also be used in other tasks such as texts and time series processing.
Convnets are typically made of convolution, pooling layers, and fully connected layers at the end. Convolutional layers are used to extract the spatial features in images, and pooling layers are used to compress the resulted feature maps from convolution layers. And fully connected layers for classification purposes.
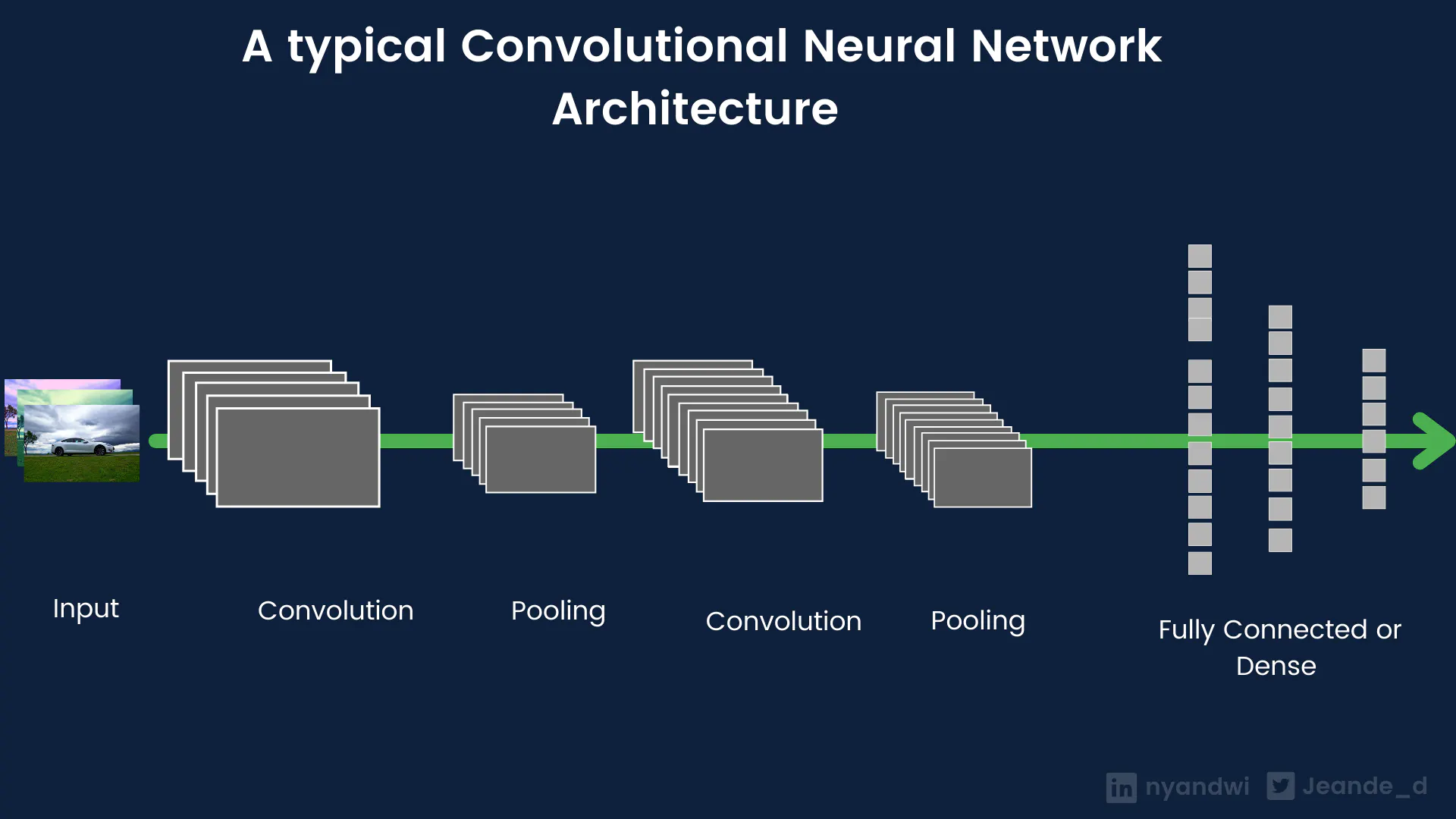 Image: Convnets architecture
Image: Convnets architecture
Convnets are of 3 dimensions. The most popular one is Conv2D that is used in images and videos divided into frames. Conv1D is used in sequential data such as texts, time series, and sounds. A popular sound architecture called WaveNet is made of 10 stacked 1D Convnets.
Conv3D is used in videos and volumetric images such as CT scans.
4.3 Recurrent Neural Networks (RNNs)¶
The standard feedforward network (or call them densely connected network) maps the input to output. RNNs go beyond that. They can maintain the recurrence of data at each time step.
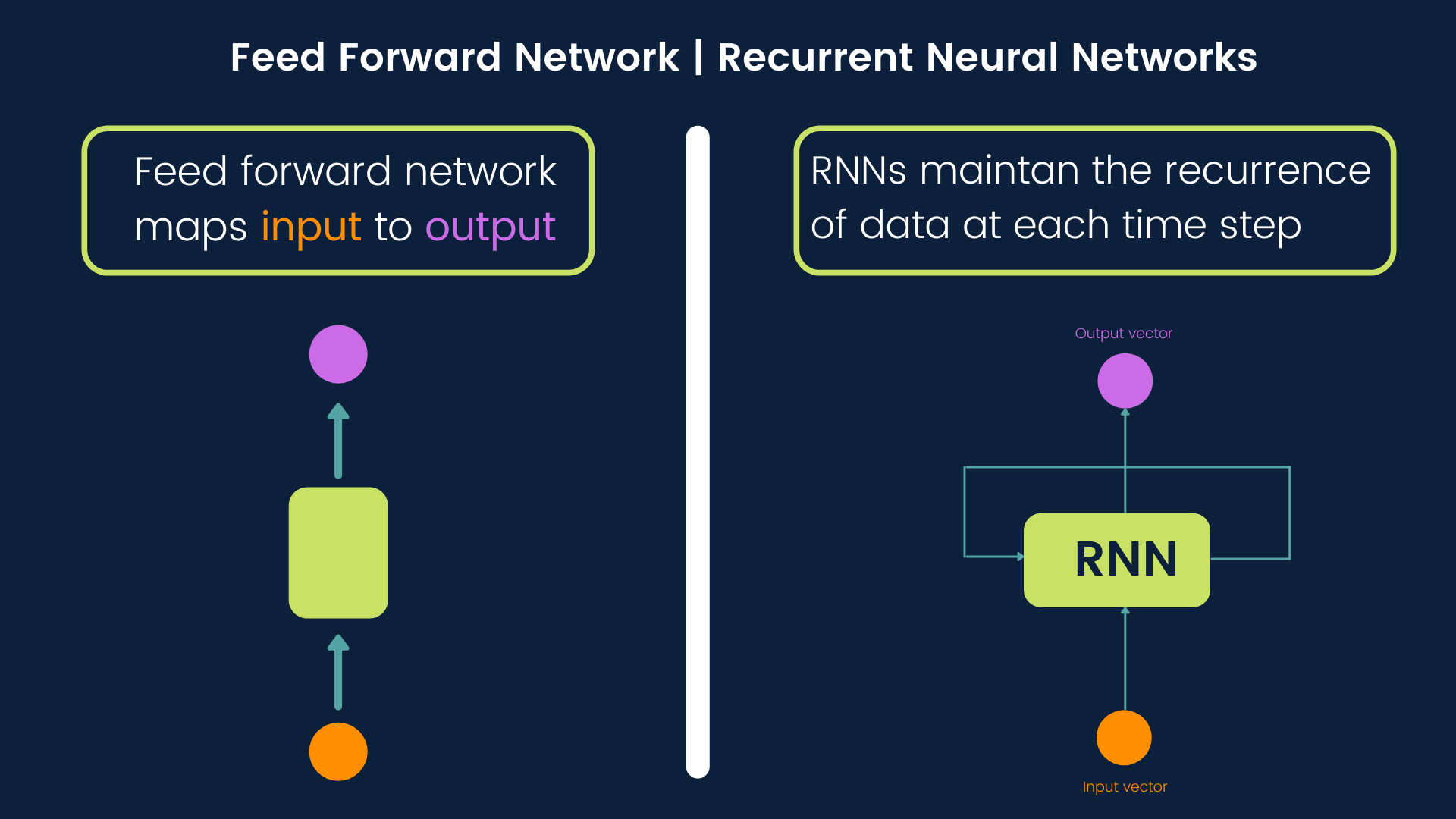 Image: Feed forward network vs recurrent neural networks
Image: Feed forward network vs recurrent neural networks
Due to their ability to preserve the recurrence of information, RNNs are commonly used in sequential data such as texts and time series.
The basic RNN cells are not efficient at handling large sequences due to a short memory problem. They also suffer from vanishing gradients.
The variant of RNNs that are able to handle long sequences is called Long Short Term Memory(LSTM). LSTM has also the ability to handle the sequences of variable lengths.
A special design difference about the LSTM cell is that it has a gate which is the basis of why it can control the flow of information over many time steps.
In short, LSTM uses gates to control the flow of information from the current time step to the next time step in the following 4 ways:
- The input gate recognizes the input sequence.
- Forget gate gets rid of all irrelevant information contained in the input sequence and store relevant information in long term memory.
- LTSM cell updates update cell's state values.
- Output gate controls the information that has to be sent to the next time step.
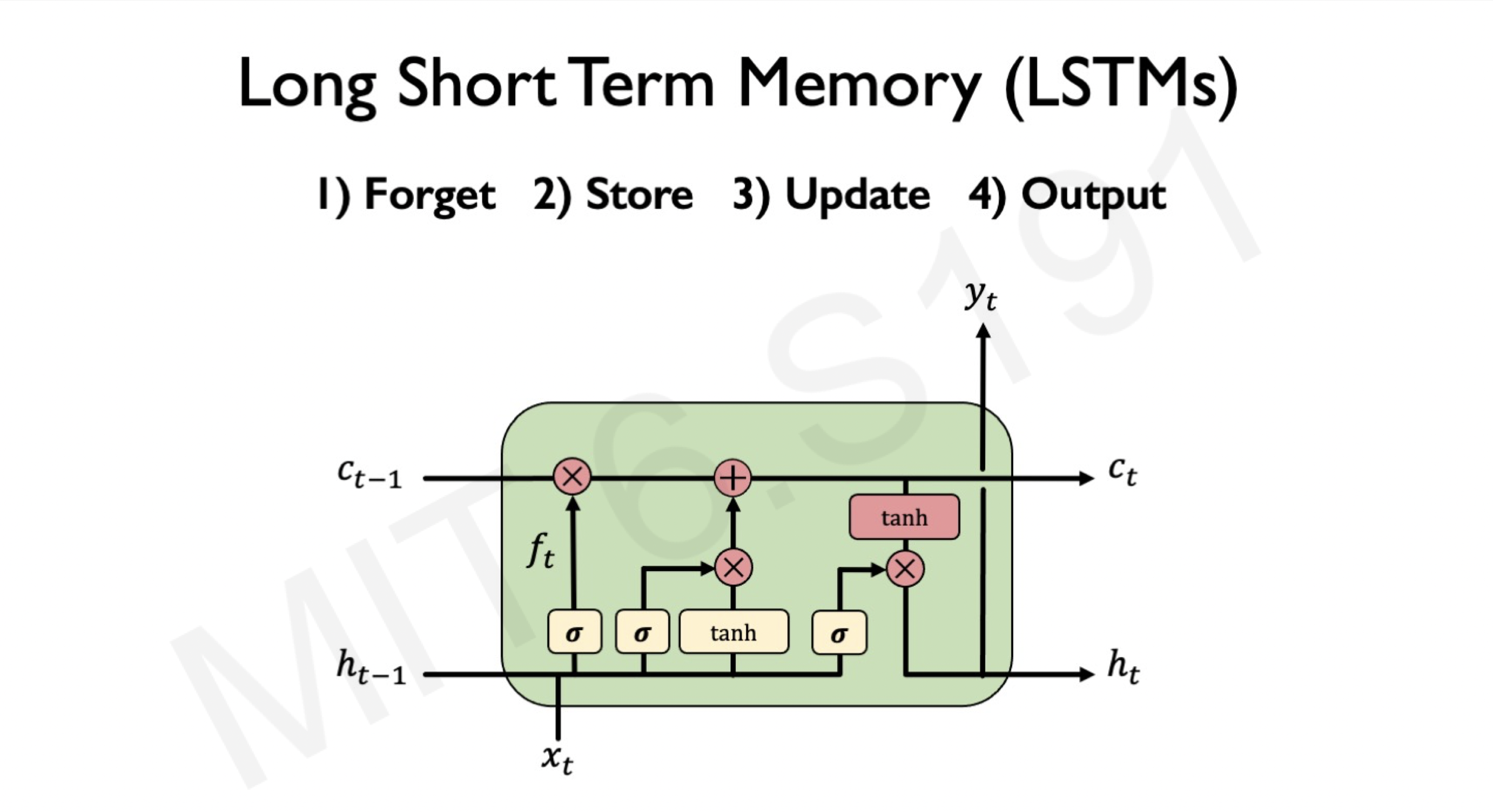
Image: LSTM architecture, Intro to Deep Learning MIT
The ability of LSTMs to handle long-term sequences makes it a suitable neural network architecture for various sequential tasks such as text classification, sentiment analysis, speech recognition, image caption generation, machine translation.
Another recurrent neural network that you will see is Gate Recurrent Unit(GRU). GRU is a simplified version of LSTMs, and it's cheaper to train.
4.4 Transformers¶
Although recurrent neural networks are still used for sequential modeling, they have short-term memory problems when used for long sequences, and they are computationally expensive. The RNN's inability to handle long sequences and expensiveness are the two most motivations of transformers.
Transformers are one of the latest groundbreaking researches in the natural language community. They are sorely based on the attention mechanisms that learn the relationships between words of the sentence and pays attention to the relevant words.
One of the most notable things about transformers is that they don't use any recurrent or convolutional layers. It's just only attention mechanisms and other standard layers like embedding layer, dense layer, and normalization layers.
They are commonly used in language tasks such as text classification, question answering, and machine translation.
There have been researches that show that they can also be used for computer vision tasks, such as image classification, object detection, image segmentation, and image captioning with visual attention.
To learn more about the transformer, check out its awesome paper.
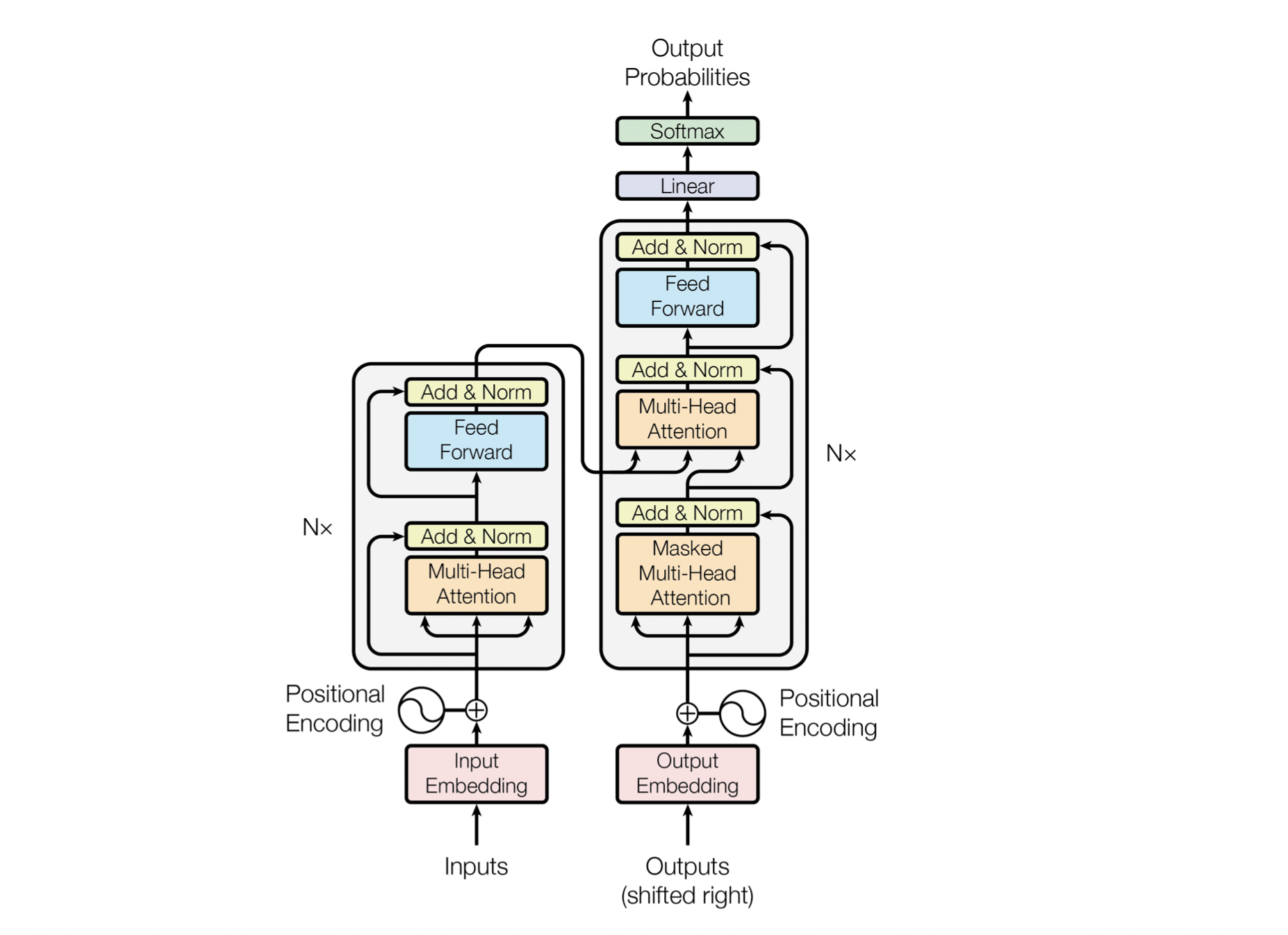
Image: Transformers architecture, Attention Is All You Need
Below is a high level summary of the common neural networks architectures.
5. Challenges in Training Neural Networks¶
Training neural networks is a big challenge and this still an area of research. For example, how do you choose a right architecture? Although the type of data can tell the most architecture that should come into picture at first, it is not a trivial question. Take an example, we know CNN as image first algorithm, bit it has been used in some natural language processing and time series tasks and it can perform well.
Also, deep learning models have many hyperparameters. Hyperparameters include things like number of layers, number of neurons, learning rate, activation functions, and optimizers (optimizers are used to reduce loss during training).
All these choises to be make it hard to train neural networks. Although there has been some techniques that can reduce number of choces to be made, such as transfer learning which motivates reusing the pretrained models, training this type of models is not an easy thing.
If you would like to learn more about training neural networks, here is a great (but complex) material about it: Why are deep neural networks hard to train?.
Also, before we go into hands-on deep learning in the next notebooks, I would like to invite you to play this game. Tinker with it and try to see how things like activation functions, input data, learning rate,...affects the neural network training. Here you Go!.¶