Machine Learning Fundamentals
We are living in the age of the intelligent machines. In the last decade, machine learning powered systems went from beating the world class chess players to now influencing most of our daily decisions like what we watch on streaming services like Netlix and Youtube. What is machine learning? And why is it important to be studying it now?
We hear that machine learning is transforming many industries, but what exactly can we use it for? And what are the set of problems that this technology is or not suited for?
This introduction will give you the basics of machine learning or these things that you will always need to know. More concretely, it will cover the high level foundational knouledge such as:
- What is machine learning?
- The difference between artificial intelligence, data science, machine learning and deep learning
- The difference between machine learning and ordinary programming
- Applications of machine learning
- When to use and when not to use machine learning
- Types of machine learning
- A typical machine learning project workflow
- Evaluation metrics
- The challenges of training machine learning systems
What is Machine Learning?
Machine learning is a new programming paradigm in which instead of explicitly programming computers to perform some tasks, we let them learn from data in order to find the underlying patterns in the data. In few words, machine learning is the science of giving the machine the ability to reason about the data.
The term machine learning was coined by Arthur Samuel in 1959. At that time, Arthur defined machine learning as a:
Field of study that gives computers the ability to learn without being explicitly programmed.
A more technical definition of machine learning was provided by Tom M. Mitchell in 1997. Here is how Tom defined machine learning:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
For the meaning of Mitchell definition on machine learning, check out this Twitter thread.
Wikipedia provides a much clear definition of machine learning:
Machine learning (ML) is the study of computer algorithms that improve automatically through experience and by the use of data. It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so. - Wikipedia.
What does that mean?
In simple words, machine learning algorithms are trained on data rather than being programmed explicitly.
Artificial Intelligence, Data Science, Machine Learning, and Deep Learning
AI or Artificial intelligence, data science, machine learning, and deep learning are used interchangeably, but they are quite different.
AI is a branch of computer science concerned with building intelligent machines capable of performing tasks at the level of human. AI seeks to mimic human. AI is an interdisciplinary field that involves machine learning, programming, robotics, data science, etc...
Machine learning on the other hand is the branch of AI and as we saw, it is concerned with giving the machine the ability to learn from data. Machine learning algorithms consists of shallow or classical algorithms such as decision trees and deep learning algorithms such as convolutional neural networks. We will learn more about these algorithms in the next parts.
Deep learning is a branch of machine learning that deals with the study of artificial neural networks and it was inspired by the human brain. Classical machine learning algorithms needs a lot of feature engineering, but deep learning algorithms can extract features in huge amount of data such as images themselves.
 Figure 1-1: The difference between AI, machine learning and deep learning
Figure 1-1: The difference between AI, machine learning and deep learning
Data science is also an interdisciplinary field that deals with using data to solve business problems with various techniques. A concise definition of data science was provided by Cassie Kozyrkov: "Data Science is the science of making data useful".
Below illustration clearly shows what's really is data science. It is a modification of a well known Conway's venn diagram.
 Figure 1-2: A slight modification of Conway's orginal venn diagram describing the field of data science.
Figure 1-2: A slight modification of Conway's orginal venn diagram describing the field of data science.
Ordinary Programming Vs Machine Learning
In ordinary programming, the job of the programmer is to clearly write every single rule that makes up the task he/she is trying to accomplish. In order to get the results, she/he must write all rules that acts up on the data.
Machine learning flips that. Instead of having to write the rules that makes up a particular application, we can feed data and results(or labels) to the machine learning model, and its job can be to determine the set of rules that map the data and labels.
Let's take a real world example. If you wanted to build an application that given a picture of person can determine if he/she is wearing or not wearing a facemask, you can just feed a bunch of images of people with and without facemasks to the machine learning model, and the model can learn the rules or patterns that map the images to whether they have a facemask or not.
You can even extends that further and use those learned rules to recognize facemasks in the images that were never seen by the that model.
 Figure 1-3: Traditional Programming vs Deep Learning
Figure 1-3: Traditional Programming vs Deep Learning
Approaching a facemask recognition problem with rule based programming would really be a hard problem. You would have to write lots of code that would later turn out to not work typically because your program will be tested on different kinds of facemasks and people in various scenarios and it's almost impossible to express that in rules. Whereas with machine learning, all you need is a bunch of images of people with and without facemasks, and there you are few steps away from getting an effective facemask recognizer. We will do this in practice in the later parts, specifically in the section of Deep Computer Vision.
Applications of Machine Learning
Before we step into further machine learning foundations, let's look at some of its most exciting applications.
Machine learning has transformed many industries, from banking, manufacturing, streaming, autonomous vehicles, agriculture, etc...In fact, most of the tech products and services we use daily possess some sorts of machine learning algorithms running in their backgrounds.
Here are the most commomly machine learning use cases:
-
Fraud detection: Banks and other financial organizations can use machine learning to detect frauds in real time.
-
Loan repayment prediction: Banks can also use the historical data of their clients to predict if they will be able to repay back the loans before granting it to them.
-
Diagnozing diseases and predicting the survival rate: Machine learning is increasingly finding its value in medicine. It can assist medical professionals in diagnozing diseases in handful of minutes. Medical professionals can also use machine learning to predict the likelihood or a course of disease or survival rate(prognosis).
-
Detecting defects in industry: Some manufacturing companies use machine vision to inspect defects in the products which ultimately result in speeding up the production process, automating the inspection task, reducing the cost and human workload. You can learn more about visual inspection in 2020 State of AI-Based Machine Vision by Landing AI.
-
Churn prediction: Organizations that provides some kinds of services can use machine learning to predict if a given customer is likely to opt out from the service or cancel subscription. This can help the organization to improve the customer experiences in order to retain the customers.
-
Spam detection: Almost all email providers such as Gmail or Outlook possess the ability to detect spams from all incoming emails to protect the users from fake promotions and scams.
-
Autonomous vehicles: Todays autonomous vehicles such as self driving cars use machine learning and deep learning systems to navigate in the roads. Using computer vision, they can be able to detect the pedestrian and traffic lights and signs and other surrounding objects.
There are many more applications of machine learning and the list could go on. For example, a given ads agency can use machine learning to learn the kinds of things that their visitors are interested in and they can use the results to place the relevant ads on the website. Same for streaming services like YouTube and Netflix. These services uses machine learning to suggest the best media to their clients based on their interests.
When And When Not to Use Machine Learning
Machine learning is an incredible technology and it has shown a lot of successes in solving various real world problems. However, like any other technology, machine learning is not suitable for solving all kinds of problems. It is thus equally important to know when and when not to use machine learning.
When to use machine learning? Machine learning is preferred when approaching:
-
Problems that are too complex to be solved by ordinary programming. For these kinds of problems, it's probably safe to try machine learning. There is no way one can write all rules that can be used for recognizing facemasks or detect spam emails accurately for example.
-
Problems that involve visual reasoning and language understanding such as image recognition, speech recognition, machine translation, etc...As we will see later, large scale perception or visual and language problems are typically handled by deep learning systems.
-
Fast changing problems where the characteristics of the problems changes with time, and there is a need to keep the system functioning well. Machine learning is suitable for these sorts of problems because machine learning algorithms can be retrained on new data.
-
Problems that are clear and have simple goals such as yes/no question or predicting a single continous number such as the quantity of product likely to be consumed in a given time. Andrew Ng., Founder of DeepLearning.AI and Adjunct Stanford Professor likes to say that machine learning (employed for automation purpose) is likely to succeed when solving a problem that takes a human a second or less to accomplish such as detecting defects in a product. Recognizing if there is a defect in a product is very simple yes/no question and take a second or less to complete.
With that said, you may not use machine learning when:
- You want the predictions made by your model to be fully explainable. This is because most machine learning models are considered to be
blackbox. - You do not have a reliable data for the problem you're trying to solve. A simple example here is trying to use machine learning for predicting stocks. Stock market data is unreliable and can change in a matter of seconds without any logical reasons, and so, it's pretty hard to for a model to learn some useful patterns from such unreliability.
- You can solve your problem with ordinary programming or a simple heuristic methods.
- You want a solution that will never need to be updated. The predictions made by machine learning models decay overtime, so if you are not ready to update data and retrain models frequently, you may have to consider non machine learning techniques.
Machine learning keeps transforming things that people never thought and with its vibrant online community, we will will keep to be surprised but in the meantime, it's a safe belt to use it in problems in which the solution can be in your favor because machine learning systems are hard to maintain.
We talked about when you should use machine learning and when you should not, but also, there are other areas where machine learning is being heavily used but with extra care and human in the loop. Example of such critical areas include medicine, self driving cars, etc...In some of those areas like self driving cars(or driver assistants), machine learning is surely a big factor but also because the cost of error made by the model can be very high, human assistance becomes important.
Types of Machine Learning Systems
In broad, there are 5 main types of machine learning systems that are:
- Supervised learning
- Unsupervised learning
- Semi-supervised learning
- Self-supervised learning
- Reinforcement learning
Let's review all of these types to get a high level understanding of what's they really mean.
Supervised Learning
Most machine learning tasks fall into supervised learning type. As the name implies, a supervised learning model is trained with input data along with some form of guidance that we can call labels. In other words, a supervised learning model maps the input data (or X in many textbooks) to output labels (y). Labels are also known as targets and they act as a description of the input data.
The example of facemask recognition that we used in above sections is a good example of supervised learning. In broad, there are 2 main kinds of supervised learning problems that are:
-
Classification problems where the task is to identify a given category from numerous categories or simply make choice between a number of categories. Another example of classification task is to identify if the incoming email is either spam or not based on the email contents.
-
Regression problems where the goal is to predict a continuous value of something. A classical example for this category is to predict the price of the used car given its features such as brand, age, number of doors, number of sits, safety level, maintenance cost, etc...
 Figure 1-4: Graphical representation of classification and regression problems
Figure 1-4: Graphical representation of classification and regression problems
Supervised learning algorithms includes shallow algorithms such as linear and logistic regression, decision trees, random forests, K-Nearest Neighbors(KNN), and support vector machines(SVM). Neural networks can be both supervised(like using them for image classification) and unsupervised.
With that said, there are other advanced tasks that falls into supervised learning type such as:
- Image captioning where the goal is to predict the caption of a given image.
- Object detection where the goal is to recognize the object in image and draw the bounding box around it.
- Image segmentation where the goal is to group the pixels that make up particular objects in the image.
 Figure 1-5: Advanced Tasks: Object detection, image segmentation, image captioning. You can test these advanced algorithms on your images using vision-explorer.
Figure 1-5: Advanced Tasks: Object detection, image segmentation, image captioning. You can test these advanced algorithms on your images using vision-explorer.
Some of those tasks can involve both classification and regression. Take an example for object detection, a task of recognizing and localizing an object in an image: it involves classification(recognizing the object among many other objects) and regression(predicting the coordinates of the objects in an image to make a bounding box).
If any of the things we are talking about sounds unfamiliar, do not worry. There is no way to explain all things at once, but as we progress, things will get clear.
Unsupervised Learning
Supervised learning algorithms are trained with data and labels. Conversely, unsupervised learning algorithms are trained on unlabelled data.
Unsupervised learning algorithms are primarily used for:
- Clustering: K-Means
- Dimension reduction and data visualization: Principal Component Analysis(PCA), t-Distributed Stochastic Neighbor Embedding(t-SNE).
There are many more algorithms that could also be used for those 2 tasks, but, we will cover K-Means, PCA, and t-SNE because they are commonly used.
Semi-supervised learning
Semi-supervised learning falls between supervised and unsupervised learning. In semi-supervised learning, a small portion of training data is labeled while the rest of the data points are not labeled.
Labeling data is one of the most challenging things in machine learning. Because it require a skilled human, it's expensive and there are always a chance of getting the labels wrong. Thus, having a way to make use of unlabelled data can improve the results of a particular task with a minimal need of labels, and ultimately reducing the time and cost that would be needed to label all the training data.
Semi-supervised learning is most notable in problems that involve working with massive datasets like internet image searches, image and audio recognition, and webpages classification. As you would imagine for example, no body that is responsible for a boring task of labelling millions of images that are uploaded daily on social media platforms like Instagram. Another example: According to sitefy, 252.000 new websites are created everyday. As you can also imagine, it would not a good use of time and resources to assign a task of labelling these websites to someone when semi-supervised learning can remove such overheads.
If you would like to learn more about the motivation behind semi-supervised learning, check this paper.
Self-supervised learning
Self-supervised learning is one of the most exciting types of machine learning that is most applicable in computer vision and robotics. While semi-supervised learning uses a small portion of labeled data, self-supervised learning uses entire unlabeled data and it does not require manual annotations, removing the need for humans in the process.
To quote this awesome paper, "producing a dataset with good labels is expensive, while unlabeled data is being generated all the time. The motivation of self- supervised learning is to make use of the large amount of unlabeled data. The main idea of self-supervised learning is to generate the labels from unlabeled data, according to the structure or characteristics of the data itself, and then train on this unsupervised data in a supervised manner."
Self-supervised learning has been one of the attractive research areas in machine learning research community. In NIPS 2016, Yann LeCun said "If intelligence is a cake, the bulk of the cake is self-supervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
If you would like to learn more about the recent advances in self-supervised learning, check this awesome repository, and this paper for a quick survey.
Reinforcement Learning
Reinforcement learning is a special type of machine learning that is most applicable in robotics and games.
In reinforcement learning, a learning system called an agent can perceives the environment, performs some actions, and gets rewarded or penalized depending on how it is performing. The main goal of the agent is to accumulate as much as rewards as possible.
The agent learns the best strategy(policy) necessary for getting the most reward itself.
Reinforcement learning holds some of the most historical AI moments. In 2016, DeepMind AlphaGo, a reinforcement learning system won Lee Sedol in Google DeepMind Challenge Match. Go is a complex board game that requires intuition, creative and strategic thinking. And Lee was one of the world class Go players. You can watch the movie of the game between AlphaGo and Lee here.
For many of us, we may not get the most of reinforcement learning, typically because of limited resources and applicability, but is it a powerful thing for those who can afford it most notably employing it in robotics and games.
Let's summarize the types of machine learning systems. By far, supervised and unsupervised learning are the two commonly used types of machine learning. Semi-supervised and self-supervised learning are also getting attractions in deep learning community, but they are still in research. We will focus more those two practical types: supervised and unsupervised.
The Typical Machine Learning Workflow
Although every machine learning problem is unique, they all follow a similar workflow. In this section, we will learn how to approach machine learning problems systematically.
Overall, a typical machine learning project workflow consists of: * Defining and formulating a problem * Collecting data * Establishing a baseline * Exploratory data analysis(EDA) * Preparing data * Selecting and training a model * Performing error analysis and improving a model * Evaluating a model * Deploying a model
Let's talk about each step in brief.
Defining a Problem
Everything starts here. Problem definition is the important and the initial step in any machine learning project. This is where you make sure you understand the problem really well. Understanding the problem will give you proper intuitions about the next steps to follow such as right learning algorithms, etc. But wait, what does it mean to understand the problem?
Understanding the problem is all about diving deep into the details of the problem at hand and asking the right questions. First, it's important to narrow down the problem until you can have a simple and a well defined goal. Here are examples of simple goals: To classify products into different categories, to predict the price of a used car given its features (such as brand, age, etc...), to recognize if a person is wearing a facemask, to divide customers into different groups that share similar behaviors, etc...As you can see, the goal can tell whether the problem is classification, regression, or clustering...
At this stage, avoid vague words. The simpler you can formulate the problem, the better things will be down the hall. It's also worth questioning if the project should be pursued. Most problems do not require machine learning.
Problem definition also goes beyond determining the goal and objective of the project to thinking about the data that will be needed. Machine learning models relies on the data, and the better models comes from better data. Do you have data that contains the things you want to predict? Models are not magical things, they are mathematical functions that takes data along with labels, and determine the patterns that can be used to make predictions on unseen data. If the data does not contain meaningful information relevant to what you want to predict, you will get poor predictions.
After you understand the problem and you have an idea of the data you want, the next step is to collect it.
Collecting Data
This is usually the next stage after formulating a problem. Before we talk about collecting data, let's even understand the meaning of data. According to wikipedia, "data are a set of values of qualitative or quantitative variables about one or more persons or objects."
There are 2 main types of data that are: * Structured data that are organized in tabular or spreadsheet format. Example of tabular data includes customer records, car sales, etc...
- Unstructure data such as images, texts, sounds, and videos. Unstructured data are not organized as the former.
Nowdays, there are lots of open-source datasets on platforms like Kaggle, Google datasets, UCL, and government websites. So, if you are solving a problem that someone solved before, it's very likely that you will find it somewhere in those platforms, or other public sources like this repository. Your job as machine learning engineer is to find the relevant data that you can use to solve the presented problem.
That said, there are times that you will have to collect your own data, especially if you are solving a problem that no one solved before. In this case, consider the time that you will have to spend collecting data and the cost. You also do not need to wait until you have your desired data points before you can start. Embrace ML development early on so that you can learn if you (really) need more data. This idea is inspired by Andrew Ng.
Also, when collecting the data, quality is better than quantity. There are times where small data but good data can outwork big poor data. The amount of data you need is going to depend on the problem you're solving and its scope, but whatever the problem is, aiming to collect good data is the way to go. If you want to learn more about the meaning of good data, read the MIT Technology review article with Andrew Ng.
Establishing a Baseline
Without a benchmark, you won't know how to evaluate your results properly. A baseline is the simplest model that can solve your problem with minimal requirements. It does not have to be a model. It can be an existing open source application, a statistical analysis or intuitions you get from data at a quick glance.
The single most purpose of a baseline is to act as a reference point when comparing the actual model with the baseline. The ultimate goal is to beat a baseline, and sometime, if you can't beat it, it might mean the project is not worth pursuing, or the baseline can be all you need.
Exploratory data analysis(EDA)
Before manipulating the data, it is quite important to learn about the dataset. This can be overlooked, but doing it well will help you know the effective strategies to be applied while cleaning the data.
Go through some values, plot some features, and try to understand the correlation between them. If the work is vision-related, visualize some images, spot what’s missing in the images. Are they diverse enough? What types of image scenarios can you add? Or what are images that can mislead the model?
Here are other things that you would want to inspect in the data:
- Duplicate values and samples
- Corrupted or data with unsupported formats (ex: having an image of .txt and with 0 Kilobytes)
- Class imbalances
- Biases
Before performing EDA, split the data into the training set, validation and test sets to avoid data leakage. The training set is used for training the model, validation set is used for evaluating the model performance during training to suggest improvements, and test set is for evaluating the final and best model performance. Validation and test set should have the same statistical distribution.
Also, to avoid data leakage, do not touch the test set in EDA or anywhere before the model training.
Data Preprocessing
Data processing is perhaps the biggest part of any machine learning project. There is a notion that Data Scientists and Machine Learning Engineers spend more than 80% of their time preparing the data and this makes sense because the real world data are messy.
In this step, it is where you convert the raw data to go in a format that can be accepted by the machine learning algorithms.
Data preprocessing is hard because there are different types of data and the way you process one is different to the other. For example, in structured data, the way you process numerical features is going to be different to categorical features. Also in unstructured data, the way you manipulate images is going to be different to how you manipulate texts or sounds.
As the next parts will cover the practical implementations of typical data preprocessing steps, let's be general about things you're likely going to deal with while manipulating the features:
-
Imputing missing values: Missing values can either be filled, removed or left as they are. There are various strategies for missing values such as mean, median, frequent imputations, backward and forward fill, and iterative imputations. The right imputation technique depends on the problem and the dataset. With the exception of tree based models, most machine learning models do not accept missing values.
-
Encoding categorical features: Categorical features are all types of features that have categorical values. For example, A gender feature having the values male and female is a categorical feature. You will want to encode such types of features. The techniques for encoding them are label encoding where you can assign 0 to Male and 0 to Female, or one hot encoding where you can get the binary representations (0s and 1s) in one hot matrix. You will see this later in practice.
-
Scaling the numeric features: Most ML models work well when the input values are scaled to small values because they can train and converge faster than they would otherwise. There are two main scaling techniques that are normalization and standardization. Normalization rescales the feautures to the values between 0 and 1 whereas standardization rescales the features to have mean of 0 and a unit standard deviation. If you are aware that your data has normal or gausian distribution, normalization can be a good choice. Otherwise, standardization will work well in many cases.
In many textbooks and courses, data preprocessing is also referred to data cleaning or data preparation. Feature engineering is also a part of data preprocessing. Feature engineering is a creative task and it require some extra knowledge about the data and the problem as it involves creating new features from existing features.
Selecting and Training a Model
Selecting, creating, and training a machine learning model is the tiniest part in any typical machine learning workflow. There are different types of models but in broad, most of them falls into these categories: linear models such as linear and logistic regression, tree-based models such as decision trees, ensemble models such as random forests, and finally neural networks.
Depending on your problem, you can choose any relevant model from these categories or tries many of them. But, it is worth mentioning that getting a model that can ultimately solve a given problem is no free lunch scenario. You have to experiment with different models to get one that works for your problem and dataset.
To reduce your modelling curve, here are a few things that you can consider while choosing a machine learning model:
-
The scope of the problem: The scope or type of your problem can give a strong signal on what learning algorithm to use. Take an example: If you are going to build an image classifier, neural networks (Convolutional Neural Networks specifically) might be your go to algorithm.
-
The size of the dataset: Linear models tend to work well in small data problems, whereas ensemble models and neural network can work well when given huge amount of data.
- The level of interpretability: If you want the predictions of your model to be explainable, neural networks may not help. Tree based models such as decision trees can be explainable compared to other models.
- Training time: Complex models (neural networks and ensemble models) will take too long to train and thus draining the computation resources. On the other hand, linear models can train faster.
As you can see, there is a trade-off during model selection. You want explainability, choose models that can provide that for you, most models don't. You have a small dataset or you care about the training time, same thing, a right model for you.
Performing Error Analysis
Performing error analysis will guide you throughout the process of improving the results of the model. The improvement can either be from the data or the model.
One of the best way to do error analysis is to plot the learning curve and to try noticing where the model is failing and what might be the reason, and the right actions that you can take to reduce the errors.
To improve the model part, you can try different model configuration values or hyperparameters. You can also try different models to see one that works well. But also, good model comes from good data, so it's important to spend time examining the results of the model with respect to the input data.
Here are questions that you can yourself iteratively in the process error analysis:
- Is the model doing poorly on all classes or is it one specific class?
- Is it because there are not enough data points for that particular class compared to other classes?
- There are trade-offs and limits on how much you can do to reduce the errors. Is there a room for improvement?
Often, the improvements will not come from tuning the model, but spending time to increase the number of training samples and data quality.
When improving the data, you can create artificial data (a.k.a data augmentation). This will work well most of the time. The whole error analysis is an iterative process, keep doing it and always aim to improve the data than the model.
If you would like to learn more about modern error analysis, I recommend you watch DeepLearning.AI event called "A Chat with Andrew on MLOps: From Model-centric to Data-centric AI."
Evaluating the Model
When you have done a great job of getting a working model, it's time to evaluate it on unseen or test data, not on training data.
And when the model works well on the test set, here comes the last step.
Deploying a Model
Model deployment is the last part in this workflow. When all the previous steps has gone right, and you are happy about the results of the model on the test set, the next step will be to deploy the model so that the users can start to make requests and get predictions or enhanced services. I call this process as machine learning in action because it what actually bring the value of machine learning.
Model deployment is not in the scope of this project. If you want to learn more about it, I recommend Machine Learning Engineering for Production (MLOps) Specialization - Deeplearning.AI..
Evaluation Metrics
Evaluation metrics are used to measure the performance of the machine learning models. Earlier in this introduction to machine learning, we saw that most problems are either regression and classification, and they are evaluated differently. Let us start with metrics that are used for evaluating regression problems
Regression Metrics
In regression tasks, the goal is to predict the continuous value. The difference between the actual value and the predicted value is called the error.
Error = Actual value - Predicted value
The square of the error over all samples is called Mean Squarred Error(MSE).
MSE = SQUARE(Actual value - Predicted value)/Number of Samples
MSE Actual Formula:
$\frac 1n\sum_{i=1}^n(y_i-\hat{y}_i)^2$
Taking the square root of the mean squared error will give the Root Mean Squared Error(RMSE). RMSE is the most used regression metric.
RMSE Actual Formula:
$\sqrt{\frac 1n\sum_{i=1}^n(y_i-\hat{y}_i)^2}$
There are times that you will work with the datasets containing outliers. A suitable metric for those kinds of datasets is Mean Absolute Error (MAE). As simple as calculating MSE, MAE is also the absolute of the error.
MAE = ABSOLUTE (Actual value - Predicted Value)
MAE Actual Formula
$\frac 1n\sum_{i=1}^n|y_i-\hat{y}_i|$
Like said, MAE is very sensitive to outliers. It is a suitable metric for all kinds of problems that are likely to have abnormal scenarios such as time series.
Classification Metrics
In classification problems, the goal is to predict the categories/class.
Accuracy is the most commonly used metric. The accuracy shows the ability of the model in making the correct predictions. Take an example, in a horse and human classifier. If you have 250 training images for horses and the same number for humans, and the model can confidently predict 400 images, then the accuracy is 400/500 = 0.8, so your model is 80% accurate.
The accuracy is simply an indicator of how your model is in making correct predictions and it will only be useful if you have a balanced dataset (like we had 250 images for horses and 250 images for humans).
When we have a skewed dataset or when there are imbalances, we need a different perspective on how we evaluate the model. Take an example, if we have 450 images for horses and 50 images for humans, there is a chance of 90% (450/500) that the horse will be correctly predicted because the dataset is dominated by the horses. But how about humans? Well, it's obvious that the model will struggle at predicting them correctly.
This is where we introduce other metrics that can be far more useful than accuracy such as precision, recall, and F1 score.
Precision shows the percentage of the positive predictions that are actually positive. To quote Google ML Crash Course, precision answer the following question: What proportion of positive identifications was actually correct?
The recall on the other hand shows the percentage of the actual positive samples that were classified correctly. It answers the question: What proportion of actual positives was identified correctly?
There is a tradeoff between precision and recall. Often, increasing precision will decrease recall and vice versa. To simplify things, we combine both of these two metrics into a single metric called the F1 score.
F1 score is the harmonic mean of precision and recall, and it shows how good the model is at classifying all classes without having to balance between precision and recall. If either precision or recall is very low, the F1 score is going to be low too.
Both accuracy, precision, and recall can be calculated easily by using a confusion matrix. A confusion matrix shows the number of correct and incorrect predictions made by a classifier in all available classes.
More intuitively, a confusion matrix is made of 4 main elements: True negatives, false negatives, true positives, and false positives.
-
True Positives(TP): Number of samples that are correctly classified as positive, and their actual label is positive.
-
False Positives (FP): Number of samples that are incorrectly classified as positive, when in fact their actual label is negative.
-
True Negatives (TN): Number of samples that are correctly classified as negative, and their actual label is negative.
-
False Negatives (FN): Number of samples that are incorrectly classified as negative, when in fact their actual label is positive.
The accuracy that we talked about is the number of correct examples over total examples. So, that is
Accuracy = (TP + TN) / (TP + TN + FP + FN)
Precision is the model accuracy on predicting positive examples.
Precision = TP / (TP + FP)
On the other hand, Recall is the model ability to predict the positive examples correctly.
Recall = TP / (TP+FN)
The higher the recall and precision, the better the model is at making accurate predictions but there is a tradeoff between them. Increasing precision will reduce the recall and vice versa.
A classifier that doesn't have false positives has a precision of 1, and a classifier that doesn't have false negatives has a recall of 1. Ideally, a perfect classifier will have the precision and recall of 1.
We can combine both precision and recall to get another metric called F1 Score. F1 Score is the harmonic mean of precision and recall.
F1 Score = 2 x(precision x recall) / (precision + recall)
Take an example of the following confusion matrix.
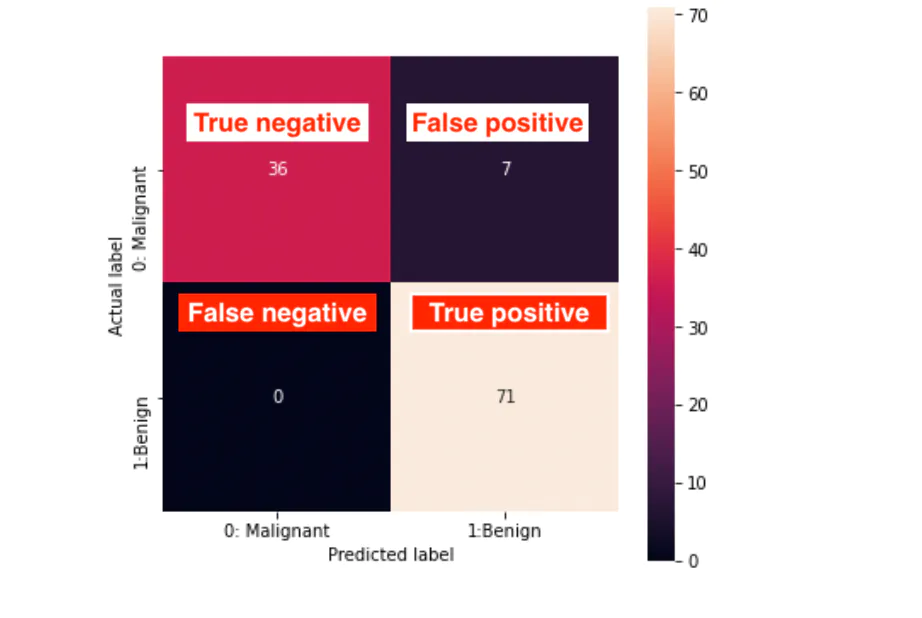
From the above confusion matrix:
Accuracy = (TP + TN) / (TP + TN + FP + FN) = (71 +36)/(71+36+7+0) = 0.93 or 93%Precision = TP / (TP + FP) = 71/(71+7) =0.91 or 91%Recall = TP / (TP + FN) = 71/(71+0) = 1, or 100%F1 score = 2PR / (P + R) = 2x0.91x1/(0.91+1) = 0.95, or 95%
Both accuracy, confusion matrix, precision, recall, and F1 score are implemented easily in Scikit-Learn, a machine learning framework used to build classical ML algorithms. We will learn more about Scikit-Learn in the next part.
The Challenges of Machine Learning Systems
Like any other technology, machine learning has challenges. What makes machine learning different to normal software development is that it involves data and codes(model). Either of those brings its own challenges, and there is usually no clear ways of handling them.
Data is the primary ingredient of machine learning, and better models are the results of better data. In real world, though, better data are rare. Most datasets are messy. They require extensive amount of time to prepare, and they can turn out to not be helpful. Also, you may have heard about data labeling. Data labeling is a challenging, time-consuming and expensive task and there are always chances of having mismatch in labels.
Even if you may have good data, you can still get poor models because it is very easy to mess up during data cleaning process. We will see some practical scenarios latter about this.
That said, models are also not perfect. Some models are computationaly expensive. Also, they tend to underfit and overfit the training data. Underfitting and overfitting deserves their own topic as they are things that we are likely to deal with.
Underfittind and Overfitting
Building a machine learning model that can fit the training data well is not a trivial task. Often, at the initial training, the model will either underfit or overfit the data. Some machine learning models take that to the extreme. Take an example, when training decision trees, it is very likely that they will overfit the data at first.
There is a trade off between underfitting/overfitting, and so it's important to understand the difference between them and how to handle each and each. Understanding and handling underfitting and overfitting is a critical task in diagonizing machine learning models.
Underfitting (Low Bias)
Underfitting happens when the model does poor on the training data. It can be caused by the fact that the model is simple for the training data or the data does not contains the things that you are trying to predict. Good data has high predictive power, and poor data has low predictive power.
Here are some of the techniques that can be used to deal with underfitting:
- Use complex models. If you are using linear models, try other complex models like Random forests or Support Vector Machines. Not to mention neural networks if you are dealing with unstructured data (images, texts, sounds)
- Add more training data and use good features. Good features have high predictive power.
- Reduce the regularization.
- If you're using neural networks, increase the number of epochs/training iterations. If the epochs are very few, the model may not be able to learn the underlying rules in data and so it will not perform well.
Overfitting (High Variance)
Overfitting is the reverse of underfitting. An overfitted model will do well on the training data but will be poor when supplied with new data (the data that the model never saw).
Overfitting is caused by using model which is too complex for the dataset and few training examples.
Here are techniques to handle overfitting:
-
Try simple models or simplify the current model. Some machine learning algorithms can be simplified. Take an example: in neural networks, you can reduce the number of layers or neurons. Also in classical algorithms like Support Vector Machines, you can try different kernels, a linear kernel is simple than a polynomial kernel.
-
Find more training data.
- Stop the training early (also know as early stopping)
- Use different regularization techniques like dropout(in neural networks).
To summarize this, it is very important to be able to understand why the model is not doing well. If the model is being poor on the data it was trained on, you know it is underfitting and you know what to do about it.
Also, beside improving and expanding the training data, you often have to tune hyperparameters to get a model that can generalize well. While there are techniques that simplified hyperparameter search(like Grid search, Random search, Keras Tuner), it is important to understand the hyperparameters of the model you are using so that you can know their proper search space.
We are getting to the end of the introduction to machine learning. Perhaps you might have seen some unfamiliar terms or concepts. That's okay. As we go from basics to practices, things will be clear.
If you would like to read some important machine learning terms, check out Google Machine Learning Glossary.
Final Notes
This was about introduction to machine learning basics. Machine learning is a field of computer science and a subfield of AI that is concerned with giving computers the ability to perform some tasks without being programmed explicitly, but rather learning from the data. Machine learning is already transforming industries. It is being used in areas like medicine, banking and finance, consumer electronics, autonomous vehicles, agriculture, etc...
We have also learned about different types of machine learning that are supervised learning, unsupervised learning, semi-supervised learning, self-supervised learning, and reinforcement learning. Also, we saw a typical flow of machine learning projects and the challenges of training learning systems, and how to overcome them.